Hackers want to hack. And if I find a way to waste some of their time, it's a slight bonus in my day. ran across a password stealer using GET requests to send the data. Let me sing you a song of wasting your space.
#! /bin/bash
count=0
while true
do
curl -silent "<redacted bad website>/index.php?action=add&username=$RANDOM&password=$RANDOM&app=$RANDOM&pcname=$RANDOM%20sys&sitename=$RANDOM" > /dev/null
let count=count+1
echo "Done $count."
done
Wednesday, September 24, 2014
usohap.exe and syshost.exe
If you searched google for usohap.exe and syshost.exe, and ended up here, you're probably infected with 8f124751c4c0e79988a3cfe5e77cb979.
Wednesday, August 27, 2014

Wednesday, August 13, 2014
Big icons make an odd bitmap
This virus had the largest icons I have seen so far at the largest being a 256x256 icon. The icon is for Thunderbird mail software.

This also seemed interesting that a bitmap if the exe file showed the icons. Don't normally see that.

This also seemed interesting that a bitmap if the exe file showed the icons. Don't normally see that.
My Ass.exe
Another mildly interesting virus. The micro folder icon would actually be pretty convincing for anyone not showing extensions of known file types (the larger folder icon is pretty bad though). Always shut that off is my reccomendation.

And I liked Trend Micro's naming.

And I liked Trend Micro's naming.
Monday, August 11, 2014
Quiet, they're listening
Looks like this malware has some mic funtions in it to turn on and off the microphone.
https://www.virustotal.com/en/file/a9e1b3c4b9fb243dee6d38257cf38aa2b06a842a88d23ad74a943806042b748b/analysis/


https://www.virustotal.com/en/file/a9e1b3c4b9fb243dee6d38257cf38aa2b06a842a88d23ad74a943806042b748b/analysis/
Thursday, July 24, 2014
ElasticSearch, LogStash, and Kibana - Beginners guide | ElasticSearch
Part 4 to ElasticSearch, LogStash, and Kibana - Beginners guide
This is where the meat of the operation is. Elasticsearch. Elasticsearch houses your imported data, indexes it, and is the way you interface with it. You can interface with ElasticSearch via its api (essentially using curl), or via things like kibana and other plugins.
But for now I'm just going over installing elasticsearch and the configuration I use. One extra thing I will touch on is a tribe set up which is awesome. I'll explain further down about tribes.
Installing:
# Get the deb file
wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.2.1.deb
# Do some java exporting
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64
# or you may need to do this one
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-i386/
# Install it
sudo dpkg -i elasticsearch-1.2.1.deb
And that's it. Control it like any other service: service elasticsearch [start,stop,restart,status]
Configuration:
There is a lot you can configure in Elasticsearch. But here is my config file (minus the comments and empty lines). Very basic, but I'll go over the parts.
File: /etc/elasticsearch/elasticsearch.yml
cluster.name: elastic-arsh
node.name: "Elastic Arlin"
node.master: true
node.data: true
index.number_of_shards: 10
index.number_of_replicas: 1
discovery.zen.ping.unicast.hosts: ["10.100.129.31"]
And that's it! Simple. Now I'll break it down.
cluster.name: es-cluster
This is the name of your elasticsearch cluster. this is the same name to use in logstash for the cluster name. It can be whatever you want.
node.name: "Elastic Server 1"
Another arbitrary name. This one is the name of the individual server running elasticsearch.
node.master: true
The node master is the one keeping track of which node has what data and where that node is located. If you have a server just hosting data, it doesn't need to be a master. If you have multiple masters, they will decide which master to use automatically.
node.data: true
This decides whether the server keeps any of the indexes on it. You can have a server be perhaps a master but not have any data on it.
index.number_of_shards: 10
index.number_of_replicas: 1
This is where things can get complicated. Shards and replicas are very related to eachother. A shard can be considered a chunk of your data. Let's say you have the default of 5 shards. This means for a days index, Elasticsearch has 5 shards (which each one is a lucene instance) to divide your data among. More shards means slower indexing, but easier to divide among the nodes in a cluster. Replicas are an exact copy of a shard. It is a copy. Which means Elasticsearch doesn't write data to it directly. Instead it writes to a shard which gets copied to a replica.
This seems redundant but it's great for clustering. Let's say you have 2 nodes in a cluster.
Node 1 has shards 1-3 and node 2 has 4-5.
Node 1 has replicas 4-5 and node 2 has 1-3.
So each node has a full set of data on it in case one node is lost. BUT you have the processing and indexing power of 2 separate nodes. When one node is lost searching is still possible because elasticsearch will rebuild the index based on the replica data it has.
There are sites that go in to more detail obviously but the correlation to remember is:
More shards = Slower Indexing
More replicas = Faster searching
discovery.zen.ping.unicast.hosts: ["10.100.10.14"]
This is the IP of the master (or comma seperated masters) for a cluster.
Tribes:
Tribes can be very useful. But they can also be a little tricky to get going. Here is the situation I use them in.
Elasticsearch transfers a lot of data between nodes. But let's say you have a datacenter in London and one in Texas. In my case no one would want the node data having to constantly go that far between two datacenters due to bandwidth usage. But setting up 2 seperate clusters would mean 2 sets of similar data with 2 interfaces to work with. And that sucks.
Enter in Tribes. An Elasticsearch tribe is when you have multiple clusters that you need to work with but don't want to share data between. So if I'l indexing logs in London and logs in Texas, I can use a Tribe setup so that both are searchable within one interface (Kibana) and they don't have to replicate their data to eachother.
You do this by adding in what I call the Tribe Chief. Set up your clusters like normal. Once they are set up, you configure the tribe chief's elasticsearch file to communicate with those clusters. The setup is very similar to a normal elasticsearch set up.
node.name: "Tribe Chief"
tribe.London.cluster.name: "London-Elasticsearch"
tribe.Texas.cluster.name: "Texas-Elasticsearch"
node.master: flase
node.data: false
discovery.zen.ping.unicast.hosts: ["10.100.10.14", "10.200.20.24"]
This tells the Tribe Chief node that it doesn't hold data and doesn't have a cluster, but to communicate with the unicast IP's listed (masters for both clusters) and use their data combined. So the Tribe Chief is what you would want to run your Kibana interface on.
There is a catch to this though. You can't have indexes that share the same name. If you do, the tribe chief will pick one index to use and ignore any others with the same name. There is a place in the logstash output where you can specify an index name. Just make sure the naming is unique per cluster.
Making the indexes from multiple clusters searchable from Kibana (running on the chief) is easy.
Open the Dashboard settings

Click on Index at the top

And then just add in the indexes from your clusters. Use the same naming scheme you used in the Logstash output. And that's it. You will see the chief join the clusters as a node and the chief will be able to search all specified indexes in any cluster without the need for clusters sharing data.
This is where the meat of the operation is. Elasticsearch. Elasticsearch houses your imported data, indexes it, and is the way you interface with it. You can interface with ElasticSearch via its api (essentially using curl), or via things like kibana and other plugins.
But for now I'm just going over installing elasticsearch and the configuration I use. One extra thing I will touch on is a tribe set up which is awesome. I'll explain further down about tribes.
Installing:
# Get the deb file
wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.2.1.deb
# Do some java exporting
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-amd64
# or you may need to do this one
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-i386/
# Install it
sudo dpkg -i elasticsearch-1.2.1.deb
And that's it. Control it like any other service: service elasticsearch [start,stop,restart,status]
Configuration:
There is a lot you can configure in Elasticsearch. But here is my config file (minus the comments and empty lines). Very basic, but I'll go over the parts.
File: /etc/elasticsearch/elasticsearch.yml
cluster.name: elastic-arsh
node.name: "Elastic Arlin"
node.master: true
node.data: true
index.number_of_shards: 10
index.number_of_replicas: 1
discovery.zen.ping.unicast.hosts: ["10.100.129.31"]
And that's it! Simple. Now I'll break it down.
cluster.name: es-cluster
This is the name of your elasticsearch cluster. this is the same name to use in logstash for the cluster name. It can be whatever you want.
node.name: "Elastic Server 1"
Another arbitrary name. This one is the name of the individual server running elasticsearch.
node.master: true
The node master is the one keeping track of which node has what data and where that node is located. If you have a server just hosting data, it doesn't need to be a master. If you have multiple masters, they will decide which master to use automatically.
node.data: true
This decides whether the server keeps any of the indexes on it. You can have a server be perhaps a master but not have any data on it.
index.number_of_shards: 10
index.number_of_replicas: 1
This is where things can get complicated. Shards and replicas are very related to eachother. A shard can be considered a chunk of your data. Let's say you have the default of 5 shards. This means for a days index, Elasticsearch has 5 shards (which each one is a lucene instance) to divide your data among. More shards means slower indexing, but easier to divide among the nodes in a cluster. Replicas are an exact copy of a shard. It is a copy. Which means Elasticsearch doesn't write data to it directly. Instead it writes to a shard which gets copied to a replica.
This seems redundant but it's great for clustering. Let's say you have 2 nodes in a cluster.
Node 1 has shards 1-3 and node 2 has 4-5.
Node 1 has replicas 4-5 and node 2 has 1-3.
So each node has a full set of data on it in case one node is lost. BUT you have the processing and indexing power of 2 separate nodes. When one node is lost searching is still possible because elasticsearch will rebuild the index based on the replica data it has.
There are sites that go in to more detail obviously but the correlation to remember is:
More shards = Slower Indexing
More replicas = Faster searching
discovery.zen.ping.unicast.hosts: ["10.100.10.14"]
This is the IP of the master (or comma seperated masters) for a cluster.
Tribes:
Tribes can be very useful. But they can also be a little tricky to get going. Here is the situation I use them in.
Elasticsearch transfers a lot of data between nodes. But let's say you have a datacenter in London and one in Texas. In my case no one would want the node data having to constantly go that far between two datacenters due to bandwidth usage. But setting up 2 seperate clusters would mean 2 sets of similar data with 2 interfaces to work with. And that sucks.
Enter in Tribes. An Elasticsearch tribe is when you have multiple clusters that you need to work with but don't want to share data between. So if I'l indexing logs in London and logs in Texas, I can use a Tribe setup so that both are searchable within one interface (Kibana) and they don't have to replicate their data to eachother.
You do this by adding in what I call the Tribe Chief. Set up your clusters like normal. Once they are set up, you configure the tribe chief's elasticsearch file to communicate with those clusters. The setup is very similar to a normal elasticsearch set up.
node.name: "Tribe Chief"
tribe.London.cluster.name: "London-Elasticsearch"
tribe.Texas.cluster.name: "Texas-Elasticsearch"
node.master: flase
node.data: false
discovery.zen.ping.unicast.hosts: ["10.100.10.14", "10.200.20.24"]
This tells the Tribe Chief node that it doesn't hold data and doesn't have a cluster, but to communicate with the unicast IP's listed (masters for both clusters) and use their data combined. So the Tribe Chief is what you would want to run your Kibana interface on.
There is a catch to this though. You can't have indexes that share the same name. If you do, the tribe chief will pick one index to use and ignore any others with the same name. There is a place in the logstash output where you can specify an index name. Just make sure the naming is unique per cluster.
Making the indexes from multiple clusters searchable from Kibana (running on the chief) is easy.
Open the Dashboard settings
Click on Index at the top
And then just add in the indexes from your clusters. Use the same naming scheme you used in the Logstash output. And that's it. You will see the chief join the clusters as a node and the chief will be able to search all specified indexes in any cluster without the need for clusters sharing data.
Tuesday, July 22, 2014
ElasticSearch, LogStash, and Kibana - Beginners guide | LogStash
Part 3 to ElasticSearch, LogStash, and Kibana - Beginners guide
Logstash. Now we're getting to the good stuff. In my set up, Logstash reads data from Redis, and sends it directly to elasticsearch. So there are 3 main parts to the logstash config. Input, Filter, and Output. The Input tells Logstash where to get data from, Filter is what to do with the data, and Output is where to send it.
Installing:
Installing is not as straightforward as the other things have been so far. Here are the straightforward steps.
Run the commands as root to make it easier and just paste them in.
Configuring:
Create your config file as /etc/logstash/conf.d/central.conf. here is again what I use.
input {
# The input section of where to get data from
redis { # Using Redis
host => "10.100.10.14" # IP of redis server
type => "log_line" # This was specified in Beaver, use consistency
data_type => "list"
key => "logstash-data" # This is the redis-namespace to look at
}
}
filter {
if [type] == "log_line" { # Since this is all I import, everything should be type log_line
# Grok is awesome but can drive you mad.
# This is my grok pattern for a custom log file, tab delimited. Lots of regex
# The main thing to know is that an almighty GROK DEBUGGER exists!
grok {
match => [ "message", "(?<timestamp>[0-9]+/[0-9]+/[0-9]+ [0-9]+:[0-9]+:[0-9]+ [AMP]+)\t(?<msg_ver>|[^\t]+)\t(?<serial>|[^\t]+)\t(?<sip>|[^\t]+)\t(?<serv>|[Server0-9\.]+)\t(?<count>|[^\t]+)\t(?<addr>|[^\t]+)\t(?<o_addr>|[^\t]+)\t(?<sub>|[^\t]+)\t(?<hits>|[^\t]+)\t(?<path>|[^\t]+)\t(?<dom>[^\t]+)" ]
add_tag => [ "es1_grok" ] # Tag it as grokked
}
date { # This tells elasticsearch how to interpret the given time stamp
# If there can be multiple formats, you can comma seperate them
match => [ "timestamp", "M/d/YYYY hh:mm:ss aa", "M/dd/YYYY hh:mm:ss aa", "MM/d/YYYY hh:mm:ss aa", "MM/dd/YYYY hh:mm:ss aa" ]
add_tag => [ "dated" ]
}
}
}
output {
# Output to elasticsearch
elasticsearch {
# IP of elasticsearch server, can be local or remote
host => "10.60.0.82"
# Cluster name, specified later in elasticsearch
cluster => "es-cluster"
# Index name, optional. Default is "logstash-%{+YYYY.MM.dd}"
index => "logstash-es-%{+YYYY.MM.dd}"
}
}
Use it like any other service: service logstash [start,stop,restart,status]
Logstash. Now we're getting to the good stuff. In my set up, Logstash reads data from Redis, and sends it directly to elasticsearch. So there are 3 main parts to the logstash config. Input, Filter, and Output. The Input tells Logstash where to get data from, Filter is what to do with the data, and Output is where to send it.
Installing:
Installing is not as straightforward as the other things have been so far. Here are the straightforward steps.
- wget -O - http://packages.elasticsearch.org/GPG-KEY-elasticsearch | apt-key add -
- sudo sh -c "echo 'deb http://packages.elasticsearch.org/logstash/1.4/debian stable main' > /etc/apt/sources.list.d/logstash.list"
- apt-get update
- apt-get install logstash
Run the commands as root to make it easier and just paste them in.
Configuring:
Create your config file as /etc/logstash/conf.d/central.conf. here is again what I use.
input {
# The input section of where to get data from
redis { # Using Redis
host => "10.100.10.14" # IP of redis server
type => "log_line" # This was specified in Beaver, use consistency
data_type => "list"
key => "logstash-data" # This is the redis-namespace to look at
}
}
filter {
if [type] == "log_line" { # Since this is all I import, everything should be type log_line
# Grok is awesome but can drive you mad.
# This is my grok pattern for a custom log file, tab delimited. Lots of regex
# The main thing to know is that an almighty GROK DEBUGGER exists!
grok {
match => [ "message", "(?<timestamp>[0-9]+/[0-9]+/[0-9]+ [0-9]+:[0-9]+:[0-9]+ [AMP]+)\t(?<msg_ver>|[^\t]+)\t(?<serial>|[^\t]+)\t(?<sip>|[^\t]+)\t(?<serv>|[Server0-9\.]+)\t(?<count>|[^\t]+)\t(?<addr>|[^\t]+)\t(?<o_addr>|[^\t]+)\t(?<sub>|[^\t]+)\t(?<hits>|[^\t]+)\t(?<path>|[^\t]+)\t(?<dom>[^\t]+)" ]
add_tag => [ "es1_grok" ] # Tag it as grokked
}
date { # This tells elasticsearch how to interpret the given time stamp
# If there can be multiple formats, you can comma seperate them
match => [ "timestamp", "M/d/YYYY hh:mm:ss aa", "M/dd/YYYY hh:mm:ss aa", "MM/d/YYYY hh:mm:ss aa", "MM/dd/YYYY hh:mm:ss aa" ]
add_tag => [ "dated" ]
}
}
}
output {
# Output to elasticsearch
elasticsearch {
# IP of elasticsearch server, can be local or remote
host => "10.60.0.82"
# Cluster name, specified later in elasticsearch
cluster => "es-cluster"
# Index name, optional. Default is "logstash-%{+YYYY.MM.dd}"
index => "logstash-es-%{+YYYY.MM.dd}"
}
}
Use it like any other service: service logstash [start,stop,restart,status]
ElasticSearch, LogStash, and Kibana - Beginners guide | Redis
Part 2 of ElasticSearch, LogStash, and Kibana - Beginners guide
What is Redis and what is it's part in the ELK life flow? I won't go deep in to this but it's best to think of Redis as a queue manager. Beaver sends log data to redis. Redis queues it up in a....queue. From there, logstash can read lines out of redis at it's own pace. And many different logstash's running on other servers can all do this at once.
Installing:
Just this: apt-get install redis-server
Configuring:
There is a lot you can do with Redis, but again here are the bsics to get it working for ELK.
This is what is in my /etc/redis/redis.conf file:
daemonize yes
pidfile /var/run/redis/redis-server.pid
port 6379
bind 10.100.10.14 # Ip address of the server
timeout 0
loglevel notice
logfile /var/log/redis/redis-server.log
databases 16
rdbcompression yes
dbfilename dump.rdb
dir /var/lib/redis
slave-serve-stale-data yes
appendonly no
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
slowlog-log-slower-than 10000
slowlog-max-len 128
vm-enabled no
vm-swap-file /var/lib/redis/redis.swap
vm-max-memory 0
vm-page-size 32
vm-pages 134217728
vm-max-threads 4
hash-max-zipmap-entries 512
hash-max-zipmap-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
activerehashing yes
The main thing to note is make sure you have the right IP address in there. I also commented out the "save" lines. These options save the redis database after a certain amount of time or certain amount of changes. This was causing some delays for me due to the amount of data. The world woudn't end if I lost the redis database (since logstash could keep up for the most part anyways) so I disabled them all.
Some useful redis commands:
Start and stop it like normal: service redis-server [start, stop, restart, status]
Redis also has a cli you can use interactively or via commands. Here two useful commands..
This one lets you see how many items are queued in the redis-namespace you configured back when setting up Beaver. It returns the number of items queued.
redis-cli -h 10.100.10.14 llen logstash-data
This one lets you see what's happening live with the nodes communicating with redis.
redis-cli -h 10.100.10.14 monitor
What is Redis and what is it's part in the ELK life flow? I won't go deep in to this but it's best to think of Redis as a queue manager. Beaver sends log data to redis. Redis queues it up in a....queue. From there, logstash can read lines out of redis at it's own pace. And many different logstash's running on other servers can all do this at once.
Installing:
Just this: apt-get install redis-server
Configuring:
There is a lot you can do with Redis, but again here are the bsics to get it working for ELK.
This is what is in my /etc/redis/redis.conf file:
daemonize yes
pidfile /var/run/redis/redis-server.pid
port 6379
bind 10.100.10.14 # Ip address of the server
timeout 0
loglevel notice
logfile /var/log/redis/redis-server.log
databases 16
rdbcompression yes
dbfilename dump.rdb
dir /var/lib/redis
slave-serve-stale-data yes
appendonly no
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
slowlog-log-slower-than 10000
slowlog-max-len 128
vm-enabled no
vm-swap-file /var/lib/redis/redis.swap
vm-max-memory 0
vm-page-size 32
vm-pages 134217728
vm-max-threads 4
hash-max-zipmap-entries 512
hash-max-zipmap-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
activerehashing yes
The main thing to note is make sure you have the right IP address in there. I also commented out the "save" lines. These options save the redis database after a certain amount of time or certain amount of changes. This was causing some delays for me due to the amount of data. The world woudn't end if I lost the redis database (since logstash could keep up for the most part anyways) so I disabled them all.
Some useful redis commands:
Start and stop it like normal: service redis-server [start, stop, restart, status]
Redis also has a cli you can use interactively or via commands. Here two useful commands..
This one lets you see how many items are queued in the redis-namespace you configured back when setting up Beaver. It returns the number of items queued.
redis-cli -h 10.100.10.14 llen logstash-data
This one lets you see what's happening live with the nodes communicating with redis.
redis-cli -h 10.100.10.14 monitor
ElasticSearch, LogStash, and Kibana - Beginners guide | Beaver
This is part 1 of my ElasticSearch, LogStash, and Kibana - Beginners guide.
What is Beaver? Beaver is very simple and straightforward. You tell it files to look at and it send off any new data added to those files to Redis.
Why Beaver? Yes, LogStash can do this as well. It can monitor files and send them to redis. But from my experience, this doesn't work the best. It can cause duplicates or even miss some items from my testing with a large amount of files (100+). With Beaver, you get a more linear flow of data as well (beaver -> redis -> logstash -> elasticsearch)
Installing:
The beaver install uses the python pip method.
If you don't have python-pip installed, do this first: apt-get install python-pip
Else do this to install Beaver: pip install Beaver
And that's it. If this doesn't work for some reason, the install method could have changed. Check their link out for the current install instructions.
Configure:
There are a lot of options to beaver you can see HERE at the projects page. Below is just a basix set up to get it working though. Paste all of the below in to a beaver.conf file somewhere. I do most of my work in the /home/logstash directory.
[beaver]
transport: redis # Tell it you are using redis
redis_url: redis://10.60.0.82:6379 # Give it the IP to your redis server (can be local too; 6379 is standard redis port)
redis_namespace: logstash-data # This is an arbitrary name for your data in redis.
logstash_version: 1
[/home/logstash/LOGS/LogstashQueue/LOG1*] # This is what or where to look for text files, wildcard use is standard
type: log_line # The type is arbitrary
tags: es1_redis,Inbound # Optional tags to add to your data, can come in handy in ElasticSearch later on
[/home/logstash/LOGS/LogstashQueue/LOG2*] # This is just another set of data to look for
type: log_line
tags: es1_redis,Outbound
And that's the end of the config file. To start up beaver, it's simple. Simply run the command "beaver -c /path/to/beaver.conf".
Now beaver does run in the foreground. If you want it to run in the background even after you logout, do the below steps.
beaver -c /path/to/beaver.conf
[Press ctrl+z ]
disown -h %1 # %1 if it was job 1, it will tell you otherwise
bg 1 # Use whatever number you did above
And that's it for beaver.
What is Beaver? Beaver is very simple and straightforward. You tell it files to look at and it send off any new data added to those files to Redis.
Why Beaver? Yes, LogStash can do this as well. It can monitor files and send them to redis. But from my experience, this doesn't work the best. It can cause duplicates or even miss some items from my testing with a large amount of files (100+). With Beaver, you get a more linear flow of data as well (beaver -> redis -> logstash -> elasticsearch)
Installing:
The beaver install uses the python pip method.
If you don't have python-pip installed, do this first: apt-get install python-pip
Else do this to install Beaver: pip install Beaver
And that's it. If this doesn't work for some reason, the install method could have changed. Check their link out for the current install instructions.
Configure:
There are a lot of options to beaver you can see HERE at the projects page. Below is just a basix set up to get it working though. Paste all of the below in to a beaver.conf file somewhere. I do most of my work in the /home/logstash directory.
[beaver]
transport: redis # Tell it you are using redis
redis_url: redis://10.60.0.82:6379 # Give it the IP to your redis server (can be local too; 6379 is standard redis port)
redis_namespace: logstash-data # This is an arbitrary name for your data in redis.
logstash_version: 1
[/home/logstash/LOGS/LogstashQueue/LOG1*] # This is what or where to look for text files, wildcard use is standard
type: log_line # The type is arbitrary
tags: es1_redis,Inbound # Optional tags to add to your data, can come in handy in ElasticSearch later on
[/home/logstash/LOGS/LogstashQueue/LOG2*] # This is just another set of data to look for
type: log_line
tags: es1_redis,Outbound
And that's the end of the config file. To start up beaver, it's simple. Simply run the command "beaver -c /path/to/beaver.conf".
Now beaver does run in the foreground. If you want it to run in the background even after you logout, do the below steps.
beaver -c /path/to/beaver.conf
[Press ctrl+z ]
disown -h %1 # %1 if it was job 1, it will tell you otherwise
bg 1 # Use whatever number you did above
And that's it for beaver.
ElasticSearch, LogStash, and Kibana - Beginners guide
If you don't know what ElasticSearch, LogStash, and Kibana are, go HERE to read more. If you know what it is but aren't sure where to start, keep reading.
I'm going to make this hopefully short and sweet but I don't guarantee that.
So what I'll try to hit on is Installing and Configuring the following:
It will be easiest to break these up in to a post for each so I'll try to set them as links above as they get written.
Here is a picture of how I run this set up. The bash script labeled is a custom script that imports and formats off-server logs. i won't be going over that though since it's beyond the scope of ELK. All you need to know is that it downloads scripts, does some format adjustment and then dumps the text files to a directory that Beaver is looking at. Beaver sends to redis, LogStash does its thing with Redis as a source, and then sends it to ElasticSearch.

I'm going to make this hopefully short and sweet but I don't guarantee that.
So what I'll try to hit on is Installing and Configuring the following:
- Beaver
- Redis
- LogStash
- ElasticSearch (and plugins)
- Kibana
- Curator
- Small monitoring script
It will be easiest to break these up in to a post for each so I'll try to set them as links above as they get written.
Here is a picture of how I run this set up. The bash script labeled is a custom script that imports and formats off-server logs. i won't be going over that though since it's beyond the scope of ELK. All you need to know is that it downloads scripts, does some format adjustment and then dumps the text files to a directory that Beaver is looking at. Beaver sends to redis, LogStash does its thing with Redis as a source, and then sends it to ElasticSearch.
Linux RamDisk script
Sometimes on my desktop I need a ram disk for processing a large amount of data. So I have a little script I simply run that asks me for a size of the ramdisk and makes it.
#! /bin/bash
#Script for an on demand ramdisk
echo -n "Size (MB):"
read SIZE
sudo mount -t tmpfs -o size="$SIZE"m none /home/mark/Desktop/RAM_Disk
#! /bin/bash
#Script for an on demand ramdisk
echo -n "Size (MB):"
read SIZE
sudo mount -t tmpfs -o size="$SIZE"m none /home/mark/Desktop/RAM_Disk
Friday, July 11, 2014
ElasticSearch De-duplicator Script
So I've been dabbling in ElasticSearch. Very cool software. More stuff to come.
I did run across an issue where I accidentally imported a bunch of duplicates. Since it was a re-import, these duplicates had different ES id's. No rhyme or reason to the duplicates order so there was no easy way to remove them. I thought surely that ES had a built in way to remove them. Maybe based on a field. Every document in my ES index has a unique guid. So essentially I needed to delete duplicates based on a guid in a field. After a lot of researching and cursing the internet godz, I made a little shell script that did it for me. Is it fast? Absolutely...not. Very slow. But I made it so it can just run in the background for a given days' index from logstash. My importing produces the occasional duplicate so this has helped me manage it while I track down that issue.
So the main requirement is that there needs to be a field in your document you can search by and is unique to only that document. Like if you fed it a field that has email addresses, this script will delete all documents with that matching field except 1.
It's quick and dirty but it works.
#! /bin/bash
# elasticsearch de-duplicator
# Get todays date for the Logstash index name
index=$(date +%Y.%m.%d)
# Or specify a date manually
if [[ -n $1 ]]
then
index=$1
fi
# Loop through deleting duplicates
while true
do
# This lists 50 unique serials by count. The serial.raw text is the field it's looking in.
curl -silent -XGET 'http://10.60.0.82:9200/logstash-'$index'/_search' -d '{"facets": {"terms": {"terms": {"field": "serial.raw","size": 50,"order": "count","exclude": []}}}}'|grep -o "\"term\":\"[a-f0-9-]\+\",\"count\":\([^1]\|[1-9][0-9]\)"|sed 's/\"term\":\"\([a-f0-9-]\+\)\",\"count\":\([0-9]\+\)/\1/' > /tmp/permadedupe.serials
# If no serials over 1 count were found, sleep
serialdupes=$(wc -l /tmp/permadedupe.serials|awk '{print $1}')
if [[ $serialdupes -eq 0 ]]
then
echo "`date`__________No duplicate serials found in $index" >> /home/logstash/dedupe.log
sleep 300
# The index has to be respecified in case it rolls in to another day
index=$(date +%Y.%m.%d)
if [[ -n $1 ]]
then
index=$1
fi
else
# For serials greater than 1 count, delete duplicates, but leave 1
for serial in `cat /tmp/permadedupe.serials`
do
# Get the id's of all the duplicated serials
curl -silent -XGET 'http://10.60.0.82:9200/logstash-'$index'/_search?q=serial.raw:'$serial''|grep -o "\",\"_id\":\"[A-Za-z0-9_-]\+\""|awk -F\" '{print $5}' > /tmp/permadedupelist
# Delete the top line since you want to keep 1 copy
sed -i '1d' /tmp/permadedupelist
# The curl command doesn't like a hyphen unless it is escaped
sed -i 's/^-/\\-/' /tmp/permadedupelist
# If duplicates do exist delete them
for line in `cat /tmp/permadedupelist`
do
curl -silent -XDELETE 'http://10.60.0.82:9200/logstash-'$index'/_query?q=_id:'$line'' &> /dev/null
echo "`date`__________ID:$line serial:$serial index:$index" >> /home/logstash/dedupe.log
done
done
fi
done
I did run across an issue where I accidentally imported a bunch of duplicates. Since it was a re-import, these duplicates had different ES id's. No rhyme or reason to the duplicates order so there was no easy way to remove them. I thought surely that ES had a built in way to remove them. Maybe based on a field. Every document in my ES index has a unique guid. So essentially I needed to delete duplicates based on a guid in a field. After a lot of researching and cursing the internet godz, I made a little shell script that did it for me. Is it fast? Absolutely...not. Very slow. But I made it so it can just run in the background for a given days' index from logstash. My importing produces the occasional duplicate so this has helped me manage it while I track down that issue.
So the main requirement is that there needs to be a field in your document you can search by and is unique to only that document. Like if you fed it a field that has email addresses, this script will delete all documents with that matching field except 1.
It's quick and dirty but it works.
#! /bin/bash
# elasticsearch de-duplicator
# Get todays date for the Logstash index name
index=$(date +%Y.%m.%d)
# Or specify a date manually
if [[ -n $1 ]]
then
index=$1
fi
# Loop through deleting duplicates
while true
do
# This lists 50 unique serials by count. The serial.raw text is the field it's looking in.
curl -silent -XGET 'http://10.60.0.82:9200/logstash-'$index'/_search' -d '{"facets": {"terms": {"terms": {"field": "serial.raw","size": 50,"order": "count","exclude": []}}}}'|grep -o "\"term\":\"[a-f0-9-]\+\",\"count\":\([^1]\|[1-9][0-9]\)"|sed 's/\"term\":\"\([a-f0-9-]\+\)\",\"count\":\([0-9]\+\)/\1/' > /tmp/permadedupe.serials
# If no serials over 1 count were found, sleep
serialdupes=$(wc -l /tmp/permadedupe.serials|awk '{print $1}')
if [[ $serialdupes -eq 0 ]]
then
echo "`date`__________No duplicate serials found in $index" >> /home/logstash/dedupe.log
sleep 300
# The index has to be respecified in case it rolls in to another day
index=$(date +%Y.%m.%d)
if [[ -n $1 ]]
then
index=$1
fi
else
# For serials greater than 1 count, delete duplicates, but leave 1
for serial in `cat /tmp/permadedupe.serials`
do
# Get the id's of all the duplicated serials
curl -silent -XGET 'http://10.60.0.82:9200/logstash-'$index'/_search?q=serial.raw:'$serial''|grep -o "\",\"_id\":\"[A-Za-z0-9_-]\+\""|awk -F\" '{print $5}' > /tmp/permadedupelist
# Delete the top line since you want to keep 1 copy
sed -i '1d' /tmp/permadedupelist
# The curl command doesn't like a hyphen unless it is escaped
sed -i 's/^-/\\-/' /tmp/permadedupelist
# If duplicates do exist delete them
for line in `cat /tmp/permadedupelist`
do
curl -silent -XDELETE 'http://10.60.0.82:9200/logstash-'$index'/_query?q=_id:'$line'' &> /dev/null
echo "`date`__________ID:$line serial:$serial index:$index" >> /home/logstash/dedupe.log
done
done
fi
done
Wednesday, June 4, 2014
Is there a game in that malware?
More interesting strings in some malware. Maybe a game? Maybe a taunting message? It had an interesting window in the code too.

And the window:

https://www.virustotal.com/en/file/b55cafa89f23950497d95fba19ed0fe96064b7e4e674ea35b361e40b5aa68c8f/analysis/1401882535/
Hits: 13/51 at the moment
MD5: f0620ad2e08b4bb26b1edc4b4b008887
And the window:
https://www.virustotal.com/en/file/b55cafa89f23950497d95fba19ed0fe96064b7e4e674ea35b361e40b5aa68c8f/analysis/1401882535/
Hits: 13/51 at the moment
MD5: f0620ad2e08b4bb26b1edc4b4b008887
Sunday, May 4, 2014
Phishing html page POST to honeyd
Found this in the wild. It was a phishing email that had an html file in it asking for the normal phishing stuff.
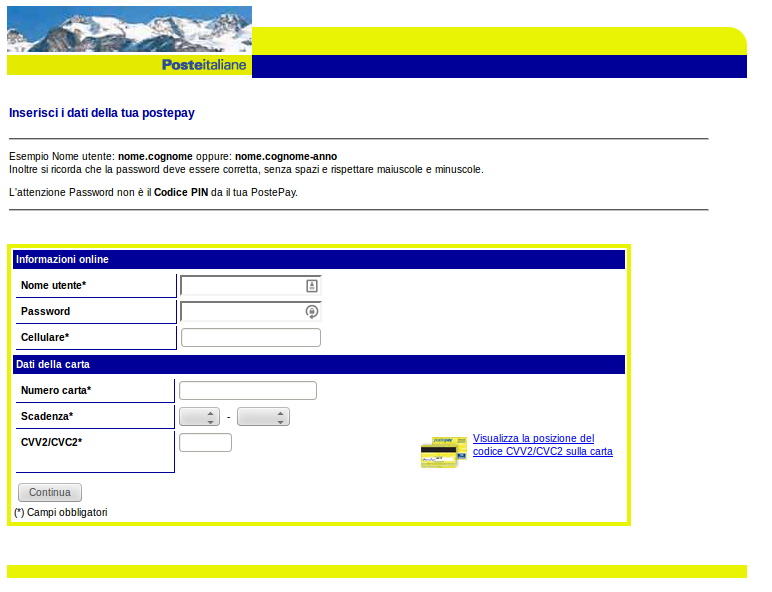
The mildly interesting part was that the post message was to a direct IP and had honeyd in the path. Might be some honeynet system that got compromised? Not sure.

The mildly interesting part was that the post message was to a direct IP and had honeyd in the path. Might be some honeynet system that got compromised? Not sure.
Monday, April 28, 2014
Some fax virus
This morning I've seen some fax viruses come in as a standard "hey you got a fax, open the attachment". The zip file is about 26k and appears to be a zbot downloader.
Two mildly interesting things with this one. One is that after executing the exe, you actually fo get an rtf file displayed as a hotel booking for some place in greece. It uses the hotels phone numbers and info. So I assume they may be a little confused shortly when people contact them saying they booked no such room.

Secondly, after that rtf file is displayed the virus sleeps for a few minutes and then gets it's payload from http://<site>/hot24/banner.png. It is of course not a png, but an executable. Yet another reason to never trust extensions.

Here are some domains the downloader was reaching out to:
jean-roussel.org
proguardians.net
pensionmagda.cz
pianossimi.fr
furiod.comyr.com
The banner.png (actually an executable) is currently recognized on VirusTotal as a 1/51. Yikes.
https://www.virustotal.com/en/file/148cc3713abba28f4e0aa5c9f3352cabe8f3e257a0325d111ea486661d47aed7/analysis/1398694595/
Two mildly interesting things with this one. One is that after executing the exe, you actually fo get an rtf file displayed as a hotel booking for some place in greece. It uses the hotels phone numbers and info. So I assume they may be a little confused shortly when people contact them saying they booked no such room.
Secondly, after that rtf file is displayed the virus sleeps for a few minutes and then gets it's payload from http://<site>/hot24/banner.png. It is of course not a png, but an executable. Yet another reason to never trust extensions.
Here are some domains the downloader was reaching out to:
jean-roussel.org
proguardians.net
pensionmagda.cz
pianossimi.fr
furiod.comyr.com
The banner.png (actually an executable) is currently recognized on VirusTotal as a 1/51. Yikes.
https://www.virustotal.com/en/file/148cc3713abba28f4e0aa5c9f3352cabe8f3e257a0325d111ea486661d47aed7/analysis/1398694595/
Friday, April 18, 2014
Java and anal sex
Another day and another funny piece of code in a virus.
md5: 1d34692a57337fa75eb62d864e406f3a

In case you wanted the whole joke...
md5: 1d34692a57337fa75eb62d864e406f3a
In case you wanted the whole joke...
|
" Saying that Java is nice because it works on every OS is like saying that anal sex is nice because it works on every gender. "
|
Wednesday, April 16, 2014
Faronics Deep Freeze
So in malware testing, vm's will not always work for you. Some of the smarter malware will recognize it is in a vm and execute code differently or not at all sometimes. This leaves me with running malware on a live system. Obviously it's incredibly easy to just load malware on to a usb drive and run it on a machine. But then that machine can no longer be used for testing future malware since it is contaminated.
Having to reinstall windows and update every time I test something would be absurd. So my normal method has been the use of a SATA hard drive duplicator and a bunch of hard drives I found around the office (I have about 15). So I would get a good clean install on a machine and pull that drive as a master drive, and use it as a source to duplicate drives any time I needed to fire up a fresh test platform. While this works fine, it's still a time consuming pain. I have to pull the drive out and wait for the duplication to finish. Since it's a byte for byte duplicator, it took around 45 minutes per drive. This was fine for most days, but on days where I had a lot of new samples, this wasn't feasible.
After some poking around online, I came across Faronics Deep Freeze software. It seemed to fit the bill for what I needed. It allowed me to create a system how I wanted it, then "freeze" it. When frozen, all changes on the pc are reverted back to the initial frozen state upon reboot. It took some playing around with for me to get used to it. I had done all my updates and software installs in a frozen state at first, so the reboot wiped it all. But eventually I got it working.
So far it has been a great success. I ran across a small exe file to test yesterday, and it ended up being a downloader for cryptolocker. So I got the normal pop up screen saying I must pay whatever yadda yadda.
After I gathered all my data, it was time to test out Deep Freeze. I clicked reboot and about 50 seconds later I was back to a clean desktop. I poked around and it looks like everything did indeed go back to how it was. I'm only on a trial but I do certainly plan to purchase this. I'm not yet convinced it's 100% bullet proof but it seems to work great so far. There are also some alternatives to it listed on wikipedia I may check out as well. Overall a good time saver so far.
Having to reinstall windows and update every time I test something would be absurd. So my normal method has been the use of a SATA hard drive duplicator and a bunch of hard drives I found around the office (I have about 15). So I would get a good clean install on a machine and pull that drive as a master drive, and use it as a source to duplicate drives any time I needed to fire up a fresh test platform. While this works fine, it's still a time consuming pain. I have to pull the drive out and wait for the duplication to finish. Since it's a byte for byte duplicator, it took around 45 minutes per drive. This was fine for most days, but on days where I had a lot of new samples, this wasn't feasible.
After some poking around online, I came across Faronics Deep Freeze software. It seemed to fit the bill for what I needed. It allowed me to create a system how I wanted it, then "freeze" it. When frozen, all changes on the pc are reverted back to the initial frozen state upon reboot. It took some playing around with for me to get used to it. I had done all my updates and software installs in a frozen state at first, so the reboot wiped it all. But eventually I got it working.
So far it has been a great success. I ran across a small exe file to test yesterday, and it ended up being a downloader for cryptolocker. So I got the normal pop up screen saying I must pay whatever yadda yadda.
 |
| oh noes |
After I gathered all my data, it was time to test out Deep Freeze. I clicked reboot and about 50 seconds later I was back to a clean desktop. I poked around and it looks like everything did indeed go back to how it was. I'm only on a trial but I do certainly plan to purchase this. I'm not yet convinced it's 100% bullet proof but it seems to work great so far. There are also some alternatives to it listed on wikipedia I may check out as well. Overall a good time saver so far.
Tuesday, April 15, 2014
A malware funny
Malware coders are people too. Yeah I hate malware, wish it would be gone, etc...but it's some time funny to see some of the things these people code. The simple things in life.
f871ad718f4b9b855f81f20901b43c91

Crap, Crappy and Crappier. Good naming schemes are important.
f871ad718f4b9b855f81f20901b43c91
Tuesday, April 8, 2014
Jpg virus
A jpg virus isn't too common but they happen. Usually the message is some sort of social media email saying "hey check out my nekked bod" with an image attached. Even a savvy user may be roped in to running this virus. It's just a jpg right? What's the harm?

That's the harm. When you open this, bad stuff happens. In this particular case only 1 of 50 av companies are finding it as malicious (Qihoo-360 shows virus.exp.wrar.2014.0401). It looks to just be a dropper and downloads a zbot after it runs.

I always use examples like this when I hear people say careful browsing and common sense are all you need to stay safe. Image viruses are nasty things to catch if you aren't paranoid and investigate a file before opening.
That's the harm. When you open this, bad stuff happens. In this particular case only 1 of 50 av companies are finding it as malicious (Qihoo-360 shows virus.exp.wrar.2014.0401). It looks to just be a dropper and downloads a zbot after it runs.
Subscribe to:
Posts (Atom)